
What Took AI So Long to Learn What Every Restaurant Knows?
For years, AI companies focused on training models. Building bigger, smarter systems. That era just ended.


TL;DR: For years, AI companies focused on training models. Building bigger, smarter systems. That era just ended. The new battleground is inference, the moment AI actually does work. And it's driving a computing shift bigger than anything we've seen since the internet. Here's why it matters to you.
Inference: The Restaurant That Explains Everything
Think about your favorite restaurant.
Years before they opened, the chef spent months perfecting recipes. Testing ingredients, refining techniques, learning what works. That's training. Expensive, time-intensive, focused entirely on building expertise.
Now the restaurant is open. Every night, customers walk in and place orders. The chef has to interpret each request, prepare the dish, and deliver it quickly. That's inference. The day-to-day operation. The actual work.
Machine learning works exactly the same way. Training is when an AI model learns patterns from massive amounts of training data. Inference is when that trained model answers your question, drafts your email, or generates an image. One is preparation. The other is execution.
For the past decade, the AI industry obsessed over training. Bigger models. More data. Smarter systems. We built incredible chefs.
But here's the thing. Restaurants don't make money perfecting recipes. They make money serving customers. And right now, AI is shifting from the kitchen to the dining room. The inflection point has arrived.
Why Inference Is Harder Than You Think
If you've ever asked ChatGPT a question, you've experienced inference. It feels instant. Effortless. Like the AI is just... thinking and responding.
Behind the scenes, it's two distinct phases happening in rapid succession.
Prefill: The AI interprets your request. Breaks it down into tokens, the fundamental units of data that language models understand. Each token is roughly three-quarters of an English word. Your question gets translated into a sequence the model can process.
Decode: The AI generates the response, one token at a time. It predicts the next most likely word, then the next, then the next, building sentences that (hopefully) answer what you asked.
This all has to happen in seconds. Ten seconds, to be specific. Research shows that if an AI takes longer than ten seconds to respond, people move on. They lose interest. The experience breaks.
Training a model? That can take weeks, even months. You can optimize for cost, run it on cheaper hardware, spread the workload over time. But inference has to be real-time. Every single time. For millions of users simultaneously.
That creates an entirely different engineering challenge.
The Numbers That Change Everything
Here's where it gets wild.
Inference requires more memory than training.
Training requires more processing power.
They're inverse problems. The chips, the data centers, the infrastructure you build for one don't automatically work for the other. This is also why you can't afford memory chips anymore - because all those models need lots of memory to do real work (inference)
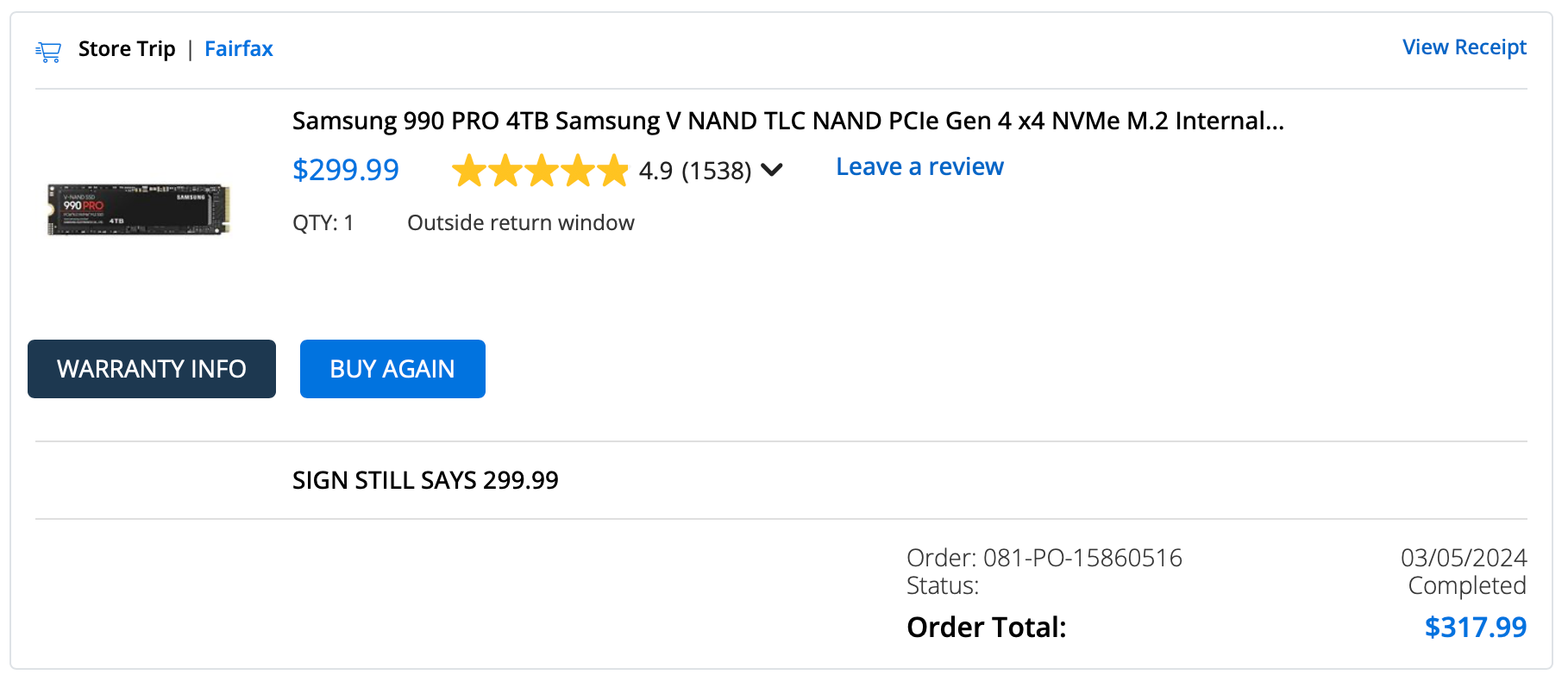
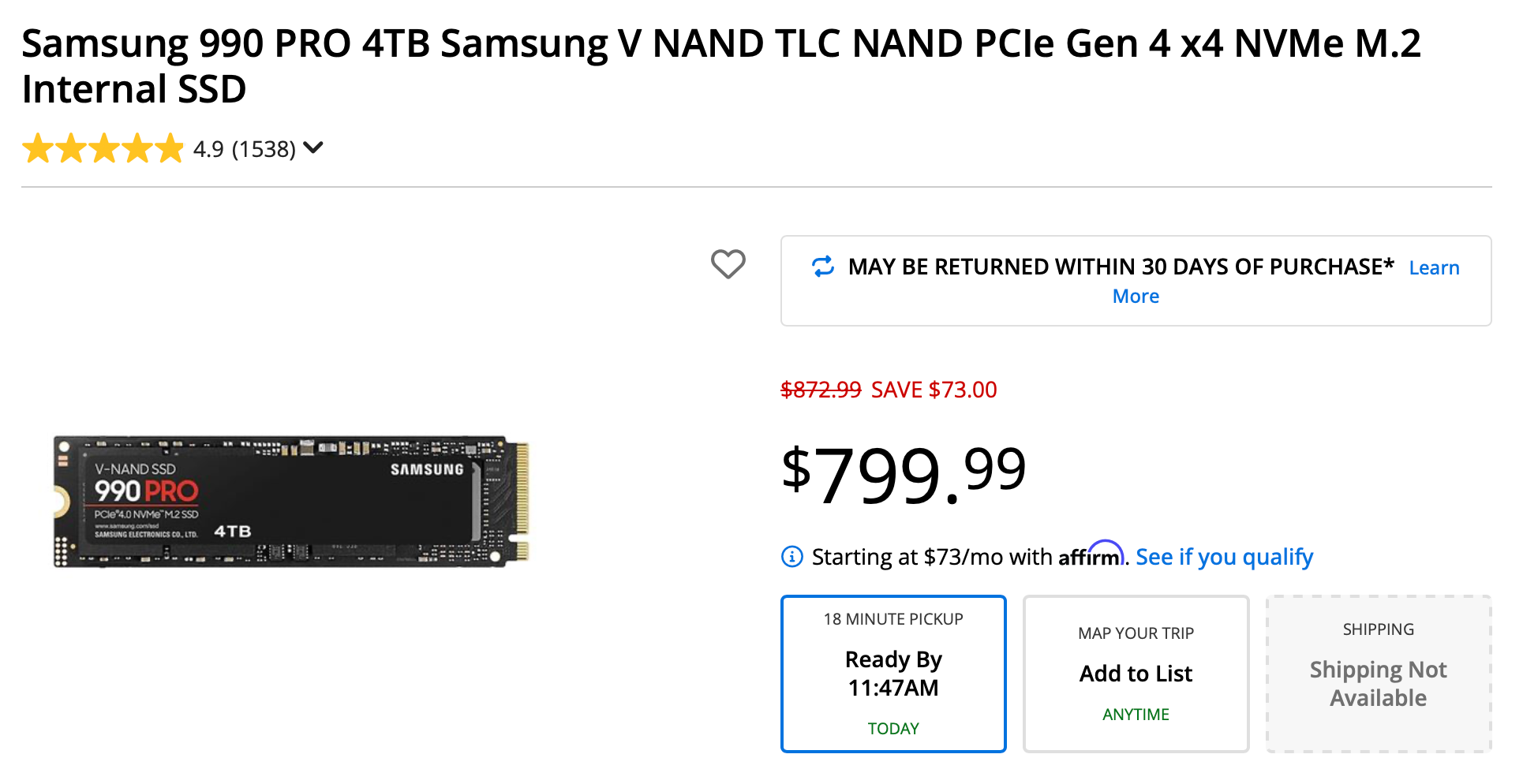
Witness the increase in RAM prices thanks to Inference: Same product, 2 years later more than 2.5x more expensive.
And the economics are flipping. Fast. For years, companies spent billions on training infrastructure because that's where the innovation happened. Build a better model, win the market. Simple.
But now that we have powerful models, the real cost is keeping them running. Answering queries. Doing actual work for actual users. Capital spending on inference infrastructure is about to surpass training spending for the first time in history. By 2029, analysts project $72 billion on inference versus $37 billion on training.
That's not a trend. That's a tectonic shift.
Why Nvidia Bought Groq for $20 Billion
Last week at GTC 2026, Jensen Huang stood on stage and said something that clicked everything into place.
"AI now has to think. In order to think, it has to inference. AI now has to do. In order to do, it has to inference."
Translation: The era of building AI is over. The era of AI doing productive work has begun.
That's why Nvidia just acquired Groq, a company specializing in inference-specific processors, for $20 billion. Not training chips. Inference chips. Purpose-built hardware optimized for the exact workload that's about to dominate computing for the next decade.
And that's why Nvidia is exploring data centers in space. Not because it's cool (though it is). Because the inference demands we're facing can't be met with Earth-based infrastructure alone. Every AI agent running right now, every ChatGPT query, every autonomous system making real-time decisions, that's all inference. Multiply that by billions of tasks per day, and you start to understand why we need computing capacity at planetary scale.
This isn't speculative. Nvidia has over $1 trillion in revenue visibility through 2027. Companies aren't buying these chips to experiment. They're buying them because they know exactly what they're building, and they know inference is the foundation.
What This Means for You
I can already hear the skeptics. "Steve, I'm not building AI models. I don't run data centers. Why does inference matter to me?"
Because inference is what makes AI useful.
When you ask an LLM to summarize an article, that's inference. When an AI agent drafts an email in your voice, that's inference. When your phone suggests the next word as you type, that's inference. When autonomous vehicles adjust to traffic in real time, that's inference.
Training gave us the capability. Inference gives us the application.
For the past two years, we've been dazzled by what AI can do in demos. Now we're entering the era where AI does things for us, constantly, in the background, as infrastructure. You won't "use AI" the way you use an app. You'll live in a world where intelligence is ambient, embedded in everything you touch.
That shift, from novelty to infrastructure, is what inference unlocks.
The Computing Shift We Didn't See Coming
Here's the part that keeps me up at night (in a good way).
For fifty years, computing followed a predictable pattern. You bought a device. You installed software. You learned how to use it. The barrier to entry was learning the machine's language.
The Digital RenAIssance flipped that script. Now the machine learns your language. You describe what you want, and AI figures out how to deliver it. But that only works if inference is fast, reliable, and ubiquitous.
Every major tech company right now is retooling for this reality. Building inference-optimized infrastructure. Designing chips that prioritize memory over raw compute power. Measuring success in tokens-per-second-per-watt and tokens-per-second-per-dollar.
Those metrics sound technical, but they translate directly into user experience. Faster inference means AI that feels more responsive, more natural, more like a companion than a tool. Cheaper inference means AI that's accessible to everyone, not just people who can afford premium subscriptions.
And permanent inference, running 24/7 across millions of devices, means AI becomes the operating system of daily life.
The Question Nobody's Asking
The AI bubble debate will rage on. People will argue whether the spending is justified, whether we're overbuilding, whether the hype matches reality.
I think that's the wrong question.
The right question is: What happens when inference becomes as ubiquitous as electricity?
Because that's where this is headed. Not "Will AI take off?" but "What world are we building once it's everywhere?"
Nvidia didn't spend $20 billion on Groq because they're guessing. They're laying the foundation for an AI-native civilization. One where computing happens everywhere, intelligence is ambient, and the gap between what you imagine and what you can create collapses entirely.
That's not hype. That's infrastructure. And infrastructure doesn't care about skepticism. It just... gets built.
How do you think AI will change your daily life once inference is everywhere? What excites you? What worries you?
Steve Chazin makes AI make sense. After three decades leading tech teams at companies like Apple and Salesforce, he's on a mission to show regular people how to use AI without fear or confusion. Welcome to the Digital RenAIssance. stevechazin.com



